动机
推荐系统选择商品展现给用户,并期待用户的正向反馈(点击、成交)。然而推荐系统并不能提前知道用户在观察到商品之后如何反馈,也就是不能提前获得本次推荐的收益,唯一能做的就是不停地尝试,并实时收集反馈以便更新自己试错的策略。目的是使得整个过程损失的收益最小。这一过程就类似与一个赌徒在赌场里玩老虎机赌博。赌徒要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么每次该选择哪个老虎机可以做到最大化收益呢?这就是多臂赌博机问题(Multi-armed bandit problem, MAB)。
MAB问题的难点是Exploitation-Exploration(E&E)两难的问题:对已知的吐钱概率比较高的老虎机,应该更多的去尝试(exploitation),以便获得一定的累计收益;对未知的或尝试次数较少的老虎机,还要分配一定的尝试机会(exploration),以免错失收益更高的选择,但同时较多的探索也意味着较高的风险(机会成本)。
冷启动问题
新上架的物品没有历史行为数据,如何分配流量以使用户满意度最大?
推荐系统中的数据循环问题
算法决定展示内容,展示内容影响用户行为,而用户行为反馈又会决定后续算法的学习,形成循环。在这种循环下,训练集和测试集与监督学习独立同分布的假设相去甚远,同时系统层面上缺乏有效探索机制的设计,可能导致模型更聚焦于局部最优。
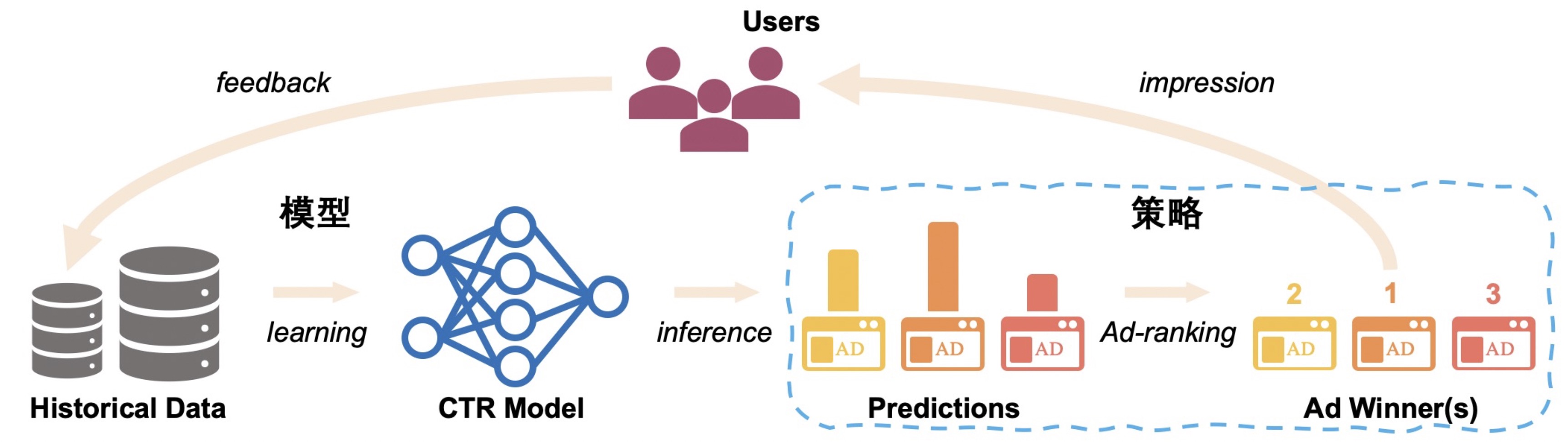
在用户行为稀疏的场景下,数据循环问题尤其显著。问题的本质:有限的数据无法获得绝对置信的预估,探索和利用(Explore&Exploit)是突破数据循环的关键。
算法概要描述
Bandit 算法能较好地平衡探索和利用问题 ( E&E 问题 ),无须事先积累大量数据就能较好地处理冷启动问题,避免根据直接收益/展现实现权重计算而产生的马太效应,避免多数长尾、新品资源没有任何展示机会。利用 Bandit 算法设计的推荐算法可以较好地解决上述问题。
根据是否考虑上下文特征,Bandit算法分为context-free bandit和contextual bandit两大类。
算法伪代码(single-play bandit algorithm):

与传统方法的区别:
每个候选商品学习一个独立的模型,避免传统大一统模型的样本分布不平衡问题
传统方法采用贪心策略,尽最大可能利用已学到的知识,易因马太效应陷入信息茧房;Bandit算法有显式的exploration机制,曝光少的物品会获得更高的展现加权
是一种在线学习方案,模型实时更新;相较A/B测试方案,能更快地收敛到最优策略
如何在一次请求中推荐多个候选物品,使用如下Multiple-Play Bandit Algorithm:
算法详细描述
Bandit算法是一类用来实现Exploitation-Exploration机制的策略。根据是否考虑上下文特征,Bandit算法分为context-free bandit和contextual bandit两大类。
1. UCB
Context-free Bandit算法有很多种,比如-greedy、softmax、Thompson Sampling、UCB(Upper Confidence Bound)等。

UCB(Upper Confidence Bound - 置信上限)就是以收益(bonus)均值的置信区间上限代表对该arm未来收益的预估值:
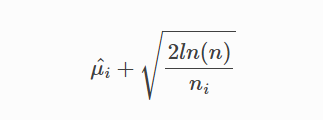

UCB在此时的决策是选择置信区间上界最大的arm。这个策略的好处是,能让没有机会尝试的arm得到更多尝试的机会,是骡子是马拉出来遛遛!
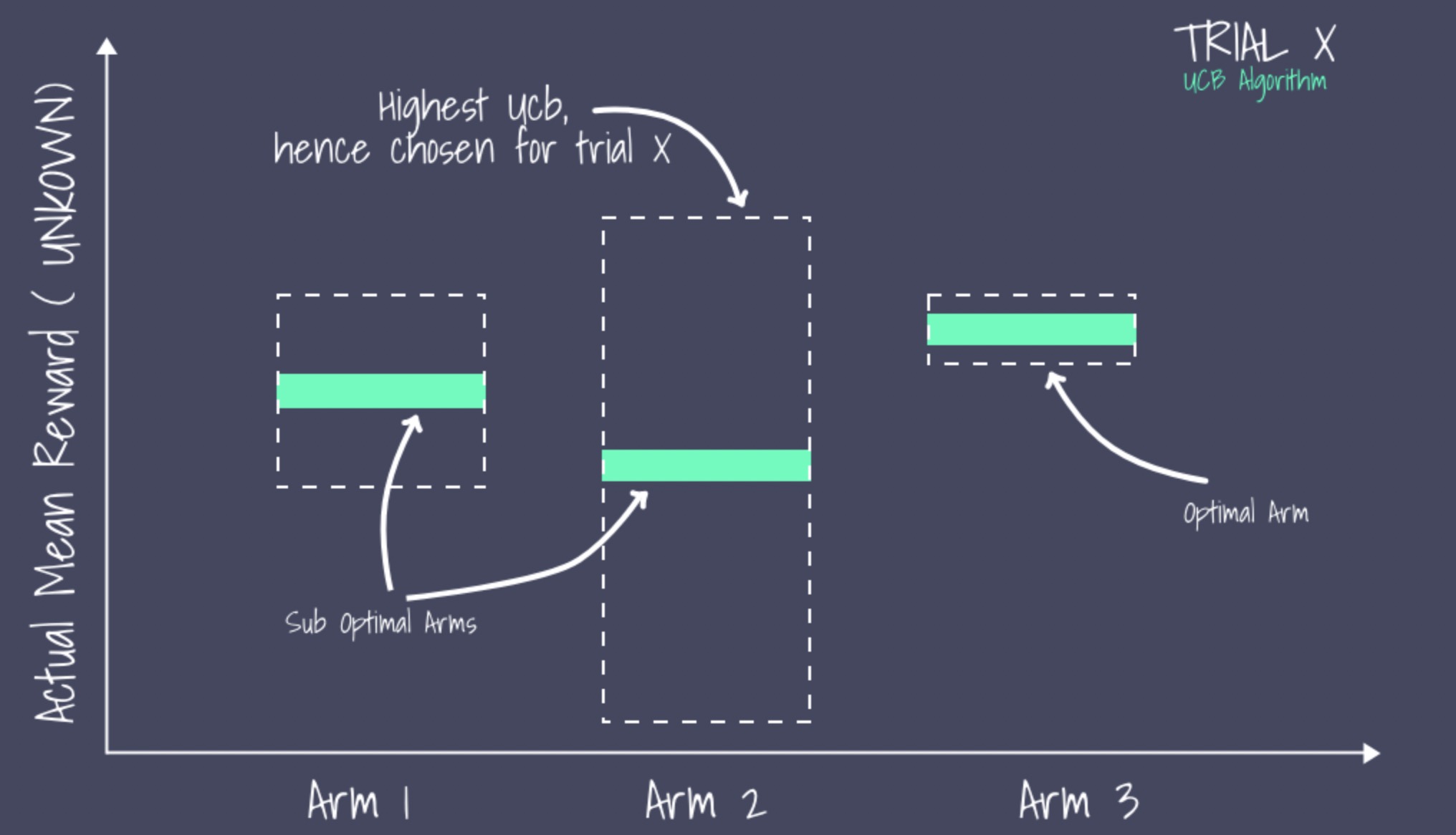
图片和部分内容来源于在生产环境的推荐系统中部署Contextual bandit (LinUCB)算法的经验和陷阱 - 知乎 (zhihu.com)
对于未知或较少尝试的arm,尽管其均值可能很低,但是由于其不确定性会导致置信区间的上界较大,从而有较大的概率触发exploration
对于已经很熟悉的arm(尝试过较多次),更多的是触发exploitation机制:如果其均值很高,会获得更多的利用机会;反之,则会减少对其尝试的机会
2. LinUCB
在推荐系统中,通常把待推荐的商品作为MAB问题的arm。UCB这样的context-free类算法,没有充分利用推荐场景的上下文信息,为所有用户的选择展现商品的策略都是相同的,忽略了用户作为一个个活生生的个体本身的兴趣点、偏好、购买力等因素都是不同的,因而,同一个商品在不同的用户、不同的情景下接受程度是不同的。故在实际的推荐系统中,context-free的MAB算法基本都不会被采用。
与context-free MAB算法对应的是Contextual Bandit算法,顾名思义,这类算法在实现E&E时考虑了上下文信息,因而更加适合实际的个性化推荐场景。

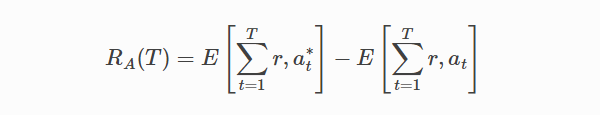
其中,T 为实验的总步数;at* 为在时间步时有最大期望收益的arm,不能提前得知。




LinUCB算法的优势:
计算复杂度与arm的数量成线性关系
支持动态变化的候选arm集合
参考资料
Contextual Bandit算法在推荐系统中的实现及应用
在生产环境的推荐系统中部署Contextual bandit算法的经验和陷阱
Using Multi-armed Bandit to Solve Cold-start Problems in Recommender Systems at Telco
A Multiple-Play Bandit Algorithm Applied to Recommender Systems
Adapting multi-armed bandits polices to contextual bandits scenarios